Shift_JISをUTF-8に変換する方法
(更新 )
そのテキストの文字コードが何で書かれているのかは、テキストエディタなどで確認することができます。
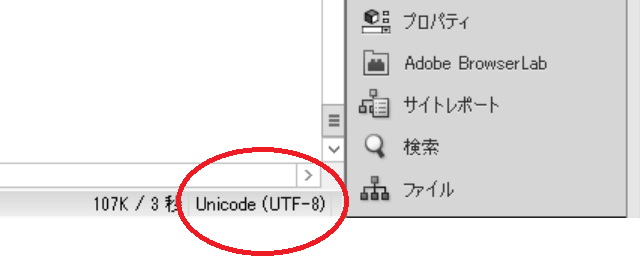
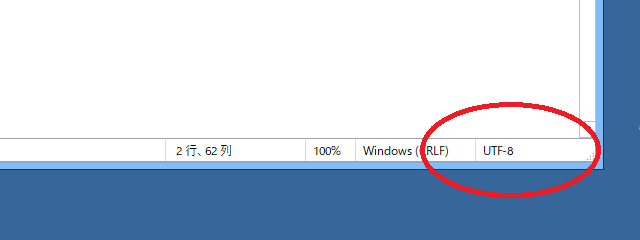
メモ帳でも「表示」→「ステータスバー」の箇所にチェックを入れると、右下の方に文字コードが表示されます。
この文字コードを変更する場合、そのまま文字コードを指定して保存すればよいだけですが、大量のファイルを一括で変換するには手間がかかります。そのような場合、Pythonにてフォルダ内のShift_JISファイルを一括でUTF-8に変換すると便利です。
ただ、HTMLファイルの場合、encodingやcharsetの箇所でもShift_JISを指定しているため、その箇所についてもUTF-8に書き換える必要があります。
<?xml version="1.0" encoding="Shift_JIS"?>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="ja" lang="ja">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=Shift_JIS" />ブラウザはXML宣言を読み飛ばすため、最初のencodingの箇所がShift_JISのままだったとしても致命的ではありませんが、charsetの箇所をそのままにしておくと文字化けの原因となります。この文字化け自体は特に問題はないものの、文字化けした状態でファイルを保存してしまうと、ファイル自体が壊れてしまうリスクがあります。
ただ、このcharsetで文字コードを判別するのはブラウザの話であって、Pythonなどのツールはcharsetを見ず、ファイルに書かれている実際のバイト列で文字コードを判別します。そして、UTF-8なら自動判別でたいていは正しく読み込まれますが、Shift_JISは日本のみのマイナーな文字コードのため、ツールが誤読して文字化けする可能性が高くなります。
そのため、手順としては、とりあえずファイル本体の文字コードをUTF-8にしてしまい、誤読を防いだ上で、charsetなどの記述内容を修正することをおすすめします。
- ファイル本体の文字コードをShift_JISからUTF-8に変換する
- HTMLファイル内からcharsetの記述を見つけ出し、「UTF-8」に書き換える
- 書き換えたHTMLを別のフォルダに出力する
ちなみに、CTRFなどの改行コードについては、どちらもASCIIで共通なため、変換はされず、直接的には関係性がありません。UTF-8のファイルでもCTRFを使用することは可能ですし、Shift_JISでもLFを使用することは可能です。
このUTF-8への変換は文字化けして失敗するケースが多いため、必ず元のファイルをバックアップした上で作業することをおすすめします。さらに、「テキスト自体の文字コードの変換」と「charsetの指定の修正」は分離し、2段階で対応するとよいでしょう。
PythonでShift_JISの文字コードをUTF-8に変換
以下のコードは、「example.com」フォルダ内のhtmlファイルをUTF-8に変換し、「new」フォルダに出力するコードになります。
以下のコードの「chardet」ライブラリをインストールするにはpipを使用します。まず、コマンドプロンプト(Windows)またはターミナル(MacまたはLinux)を開き、以下のコマンドを入力して実行します。
pip install chardet「example.com」の箇所は修正し、フォルダと同じ階層にconvert.pyファイルを設置して実行してください。
■convert.py
Python|ソースコードを表示する
import os
import chardet
from pathlib import Path
from shutil import copyfile
src_dir = Path("example.com")
dest_dir = Path("new")
# エラーログファイルのパス
error_log_path = 'error_log.txt'
with open(error_log_path, 'w', encoding='utf-8') as error_log:
for ext in ["*.html", "*.htm"]: # 追加
for src_path in src_dir.glob("**/" + ext): # 変更
# 変換後のパスを作成
relative_path = src_path.relative_to(src_dir)
dest_path = dest_dir / relative_path
dest_path.parent.mkdir(parents=True, exist_ok=True)
# ファイルの文字コードを判定
rawdata = open(src_path, 'rb').read()
result = chardet.detect(rawdata)
charenc = result['encoding']
if charenc == 'utf-8':
# 既にutf-8のファイルはそのままコピーし、ログに書き出す
copyfile(src_path, dest_path)
error_log.write(f"Already UTF-8, copied: {src_path}\n")
continue
# Shift_JISのバリエーションを考慮して読み込みを試みる
try:
if charenc in ['shift_jis', 'cp932', 'shift_jisx0213', 'euc_jp', 'iso2022_jp']:
with src_path.open(mode='r', encoding=charenc, errors='ignore') as inf:
content = inf.read()
else:
with src_path.open(mode='r', encoding='shift_jis', errors='ignore') as inf:
content = inf.read()
with dest_path.open(mode='w', encoding='utf8') as outf:
outf.write(content)
except Exception as e:
# エラーメッセージをログに書き出す
error_log.write(f"Failed to convert file: {src_path}, Error: {e}\n") コピー
コピー

何等かの事情でエラーが発しした場合は、エラーログが出力されます。
charsetでのShift_JISの指定をUTF-8に修正
上記にて、「example.com」フォルダ内のファイルがUTF-8に変換され、「new」フォルダ内に入っていると思います。
この「new」フォルダ内のHTMLファイルには、以下のように「encoding="Shift_JIS"」や「charset="Shift_JIS"」などと記載されている箇所があるため、以下のコードでこちらもUTF-8に修正して「neo」フォルダに出力します。
<?xml version="1.0" encoding="Shift_JIS"?>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="ja" lang="ja">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=Shift_JIS" />もしファイルの文字コードが「Shift_JIS」のままだった場合はそのままスキップし、「UTF-8」だった場合のみ、上記の箇所を修正します。
■charset.py
Python|ソースコードを表示する
import os
import shutil
import chardet
import re
import logging
# ロギングの設定
logging.basicConfig(filename='error.log', level=logging.ERROR)
# 入力・出力先のディレクトリ
input_dir = 'new'
output_dir = 'neo'
# 出力先ディレクトリが存在しない場合、作成
os.makedirs(output_dir, exist_ok=True)
# 入力ディレクトリとそのすべてのサブディレクトリを順に処理
for dirpath, dirnames, filenames in os.walk(input_dir):
for filename in filenames:
if not filename.endswith(('.html', '.htm')): # .htmlまたは.htmファイル以外は無視
continue
filepath = os.path.join(dirpath, filename)
# ファイルをバイナリモードで読み込み、エンコーディングを推定
with open(filepath, 'rb') as file:
rawdata = file.read()
result = chardet.detect(rawdata)
file_encoding = result['encoding']
# Shift_JISのままであるべきファイルが存在する場合
if file_encoding.lower() == 'shift_jis':
logging.error(f'{filepath}: Shift_JIS detected.')
# 出力先フォルダパスを作成し、存在しない場合は作成
relative_dir = os.path.relpath(dirpath, input_dir)
new_dirpath = os.path.join(output_dir, relative_dir)
os.makedirs(new_dirpath, exist_ok=True)
# 出力先にそのままコピー
new_filepath = os.path.join(new_dirpath, filename)
shutil.copy(filepath, new_filepath)
elif file_encoding.lower() == 'utf-8':
with open(filepath, 'r', encoding='utf-8') as file:
contents = file.read()
# charsetがShift_JISになっているか確認し、UTF-8に変更
contents = re.sub(r'charset=["\']?shift_jis["\']?', 'charset="utf-8"', contents, flags=re.I)
contents = re.sub(r'encoding=["\']?Shift_JIS["\']?', 'encoding="utf-8"', contents, flags=re.I)
# 出力先フォルダパスを作成し、存在しない場合は作成
relative_dir = os.path.relpath(dirpath, input_dir)
new_dirpath = os.path.join(output_dir, relative_dir)
os.makedirs(new_dirpath, exist_ok=True)
new_filepath = os.path.join(new_dirpath, filename)
with open(new_filepath, 'w', encoding='utf-8') as new_file:
new_file.write(contents)最終的に、「neo」フォルダ内にUTF-8のHTMLファイルが出力されているはずです。ただし、Shift_JISには様々な種類があるため、完璧に変換するのは困難かと思います。どうしても文字化けしてしまう文字が出てきてしまうかもしれません。
ファイルの文字コードがUTF8かチェックする方法
最後に、全てのファイルがUTF-8に変換されているかをチェックします。
以下のスクリプトは、「neo」フォルダ内をチェックし、UTF-8以外のファイルをlist.txtに書き出すものです。
■check.py
Python|ソースコードを表示する
import chardet
from pathlib import Path
src_dir = Path("neo")
# 結果を保存するテキストファイルのパス
list_txt_path = 'list.txt'
non_utf8_files = []
# .htmlと.htmの両方を探す
for extension in ['**/*.html', '**/*.htm']:
for src_path in src_dir.glob(extension):
try:
# ファイルの文字コードを判定
with open(src_path, 'rb') as f:
rawdata = f.read()
result = chardet.detect(rawdata)
charenc = result['encoding']
if charenc != 'utf-8':
# utf-8以外のファイルのパスをリストに追加
non_utf8_files.append(str(src_path))
except Exception as e:
print(f"Failed to check file: {src_path}, Error: {e}")
# リストの内容をテキストファイルに書き出す
with open(list_txt_path, 'w', encoding='utf-8') as list_txt:
if non_utf8_files:
for filepath in non_utf8_files:
list_txt.write(filepath + '\n')
else:
list_txt.write('すべてのファイルがUTF-8で、list.txtが空です。\n')全てUTF-8だった場合、「すべてのファイルがUTF-8で、list.txtが空です。」と表示されます。
チェックするファイルが大量にある場合は時間がかかるかもしれませんが、こちらは、単にチェックするのみで、元のHTMLファイルに変更は加えられません。
フォルダ自体が大量にあるホームページファイルの場合にも、「neo」の箇所を適宜変更し、同じ階層に上記のcheck.pyファイルを設置して実行すれば、調べることができます。