RSS/Atomフィードの作り方
現在、最新情報のチェックはSNSが主流となりましたので、一般ユーザーがRSS/Atomフィードを利用することはほとんどなくなりました。
けれども、検索エンジンがサイトの最新記事をチェックする際、サイトマップには全てのページが掲載されているため、大規模なサイトでは膨大なURLとなり、あまり効率的ではありません。
その点、RSS/Atomフィードには最新の5~20記事程度しか掲載されてないため、最新情報をチェックするのに効率がよく、現在でも検索エンジンやコアなユーザーに利用されています。
当ホームページでは、トップページのみにAtomフィードを設置していますが、以下のようなものになります。
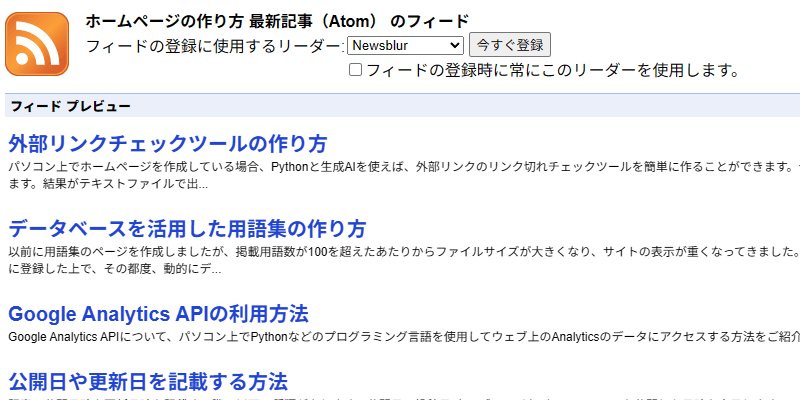
RSS/Atomフィードといえば、ブログ特有の機能との印象もありますが、rss.xmlやatom.xmlファイルを作成してアップロードし、<link rel="alternate"で指定するだけなので、ホームページ形式のサイトでも問題なく設置することができます。
AtomフィードとRSSフィード、作成するならどっち?
配信フィードといえば、RSSの方が知名度は高いため、rss.xml形式で作成すべきとは思います。ただ、実際にRSSフィードを作成しようとしますと、その仕様にあいまいな部分が多く、作成しずらい側面があるため、当ホームページではAtomフィードのみで対応しています。
このRSSとAtomの概要は以下の流れになります。
- 1999年:RSS 0.90 / 0.91
Netscape社がポータルサイト用に開発。 - 2000年:RSS 1.0
「RDF」を取り入れた厳格なグループが開発したものの、構造が複雑であまり普及しなかった。 - 2002年:RSS 2.0
RSS 0.91の流れを汲み、RDFの複雑さを排除しつつ、誰でも簡単に書けるシンプルさで爆発的に普及した。知名度が高い。 - 2005年:Atom 1.0
RSS 2.0の曖昧さを解決するため、Googleなどのエンジニアが協力してIETFで策定されたインターネット標準の規格(RFC 4287)。Atom 1.0が最終的な完成形でその後は更新されていない。
当サイトでも一応はRSSフィードも作成してみましたが、自由であるが故に「果たしてこれでいいのだろうか?」という一抹の疑念があります。Atomが登場した理由もそのあたりにあるものと思いますが、Atomは仕様が明確に決まっているため、作成はしやすいです。
可能であれば、両方を作成することをおすすめしますが、Atomフィードだけでも問題はないかと思います。
ちなみに、AtomであってもRSSアイコンを使っても特に問題はありません。「RSS」はフィード全般を象徴する代名詞となっているので、むしろそちらの方が親切かと思います。
PythonのfeedgenライブラリでRSS/Atomフィードを作成する方法
このRSS/Atomフィードをホームページで作成する際、Pythonのfeedgenライブラリを利用すると便利です。サイトによって事情は異なると思いますが、当ホームページでは以下の手順でatom.xmlとrss.xmlファイルを出力されるようにしました。
- ①Pythonのfeedgenライブラリをpipでインストール
- ②サイトマップ(sitemap.xml)から全ページのURL情報を取得
- ③各URLに対応するPC内のホームページファイルについて、HTMLを解析してJSON-LDに公開日'datePublished'の記載があるかをチェック
- ④公開日があるURLについては、タイトルや概要も合わせて取得
- ⑤日付順にならべて最新記事の5件を取得
- ⑥Feedgeneratorで最新記事5件のURLやタイトル、概要などを組み立て、atom.xmlやrss.xmlを作成
RSS/Atomフィードの作成には、タイトルや概要などの項目も必要なため、sitemap.xmlに記載されているURLと日付のリストのみでは作成できません。sitemap.xmlで全記事のリストを取得した上で、それぞれ該当するHTMLファイルの中身をチェックし、タイトル、概要なども取得する必要があります。
また、公開日の"datePublished"ではなく、最終更新の"dateModified"を基準にして並べてしまうと、誤字を修正しただけでも最新記事として表示されてしまいます。RSS/Atomフィードの主旨は、最新記事を読みたい人に通知する機能なため、当サイトではJSON-LDに記載している公開日の"datePublished"を基準としました。
もしJSON-LDを記載していない場合、ページ内の公開日の日付に<time>タグを使用していれば、代替できるかもしれませんが、いずれにしましても更新日ではなく、公開日を基準に使用することをおすすめします。
Atomフィード作成用のPythonコードのサンプル
IETFの公式サイトにAtomフィードの例が記載されていますが、こちらと同じようにatom.xmlを作成すれば問題ないかと思います。
<?xml version="1.0" encoding="utf-8"?>
<feed xmlns="http://www.w3.org/2005/Atom">
<title>Example Feed</title>
<link href="http://example.org/"/>
<updated>2003-12-13T18:30:02Z</updated>
<author>
<name>John Doe</name>
</author>
<id>urn:uuid:60a76c80-d399-11d9-b93C-0003939e0af6</id>
<entry>
<title>Atom-Powered Robots Run Amok</title>
<link href="http://example.org/2003/12/13/atom03"/>
<id>urn:uuid:1225c695-cfb8-4ebb-aaaa-80da344efa6a</id>
<updated>2003-12-13T18:30:02Z</updated>
<summary>Some text.</summary>
</entry>
</feed>
上記のテンプレートを参考に手動で作成することもできますが、Pythonのfeedgenライブラリを利用して自動化すると便利です。具体的なコードのサンプルは以下のようになります。
■atom.pyのサンプル
赤字の部分は当サイト固有のものですので、生成AIと相談しながら適宜書き換えてください。
HTMLページ内にjson-ld('application/ld+json')が記載されていれば、そちらの公開日('datePublished')やタイトル('headline')を取得して、最新記事の順にatom.xmlを組み立てるコードです。summaryに記載する内容については、mainタグ内からタイトルや日付を除外して取得するようにしました。
import os import json from bs4 import BeautifulSoup from feedgen.feed import FeedGenerator from datetime import datetime, timezone, timedelta # --- 設定項目 --- BASE_DIR = os.path.dirname(os.path.abspath(__file__)) OUTPUT_DIR = os.path.join(BASE_DIR, 'output') OUTPUT_PATH = os.path.join(OUTPUT_DIR, 'atom.xml') SOURCE_DIR = r'C:\Users\ホームページファイルのパス' SITEMAP_PATH = os.path.join(SOURCE_DIR, 'sitemap.xml') SITE_URL = 'https://www.example.com/' JST = timezone(timedelta(hours=+9)) def get_local_path(url): relative_path = url.replace(SITE_URL, '').replace('/', os.sep) if relative_path.endswith(os.sep) or not relative_path: relative_path = os.path.join(relative_path, 'index.html') return os.path.join(SOURCE_DIR, relative_path) def extract_info(file_path, url): if not os.path.exists(file_path): return None try: with open(file_path, 'r', encoding='utf-8') as f: soup = BeautifulSoup(f, 'html.parser') json_ld = soup.find('script', type='application/ld+json') if not json_ld: return None data = json.loads(json_ld.string) if isinstance(data, list): data = data[0] date_str = data.get('datePublished') if not date_str: return None dt = datetime.fromisoformat(date_str).replace(microsecond=0) if dt.tzinfo is None: dt = dt.replace(tzinfo=JST) title = data.get('headline') or (soup.title.string if soup.title else "No Title") # --- summaryに記載する内容を抽出 --- content = "" main_tag = soup.find('main') if main_tag: import copy temp_main = copy.copy(main_tag) # 1. h1タグを削除 if temp_main.h1: temp_main.h1.decompose() # 2. id="published" の要素を削除 published_tag = temp_main.find(id="published") if published_tag: published_tag.decompose() # 3. 本文のみを150文字抽出 content = temp_main.get_text(strip=True)[:150] + "..." else: content = "" return {'title': title, 'date': dt, 'url': url, 'desc': content} except: return None def main(): if not os.path.exists(OUTPUT_DIR): os.makedirs(OUTPUT_DIR) print(f"フォルダを作成しました: {OUTPUT_DIR}") with open(SITEMAP_PATH, 'r', encoding='utf-8') as f: urls = [loc.text for loc in BeautifulSoup(f, 'xml').find_all('loc')] entries = [] print(f"{len(urls)} 件のファイルをスキャン中...") for url in urls: info = extract_info(get_local_path(url), url) if info: entries.append(info) # 新しい順にソートして上位5件を取得後、書き込み順のために逆転 entries.sort(key=lambda x: x['date'], reverse=True) final_entries = entries[:5] final_entries.reverse() fg = FeedGenerator() fg.id(SITE_URL) fg.title('サイト名 最新記事(Atom)') fg.link(href=SITE_URL, rel='alternate') fg.link(href=f"{SITE_URL}atom.xml", rel='self') fg.language('ja') fg.updated(datetime.now(JST).replace(microsecond=0)) fg.author({'name': '管理者名', 'email': 'info@example.com'}) for item in final_entries: fe = fg.add_entry() fe.id(item['url']) fe.title(item['title']) fe.link(href=item['url']) fe.updated(item['date']) fe.summary(item['desc']) fg.atom_file(OUTPUT_PATH, pretty=True) print(f"Atomフィードを生成しました: {OUTPUT_PATH}") if __name__ == '__main__': main()コピー

実行すると、「output」フォルダ内にatom.xmlファイルが出来ているはずですので、サーバーにアップロードしましょう。
W3CにRSS/Atomフィードのバリデーターがあるので、エラーがないかチェックしてみることをおすすめします。
最後に、htmlのheadタグ内に以下のコードを設定すれば完了です。
<link rel="alternate" type="application/atom+xml" title="サイト名 最新記事 (Atom)" href="https://www.example.com/atom.xml">トップページにだけ記載するのでも問題はないかと思います。
RSSフィード作成用のPythonコードのサンプル
RSSフィードについては、公式サイトにRSS 2.0のサンプルが公開されているので、そちらを参考にすることをおすすめします。「2.0」の箇所にxmlファイルで公開されているため、右クリックでリンク先を保存したのち、メモ帳などで閲覧することができます。
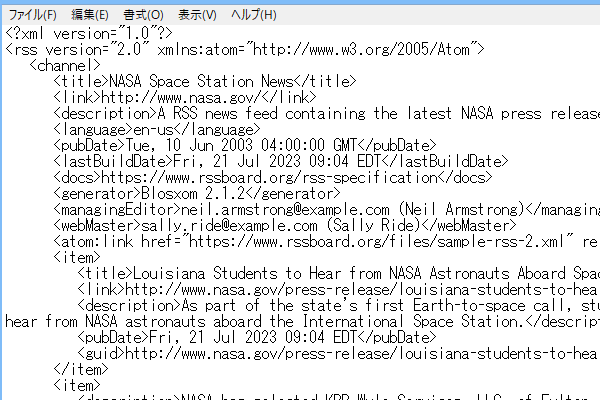
このサンプルを単純化しますと、以下のようになります。
<?xml version="1.0"?>
<rss version="2.0" xmlns:atom="http://www.w3.org/2005/Atom">
<channel>
<title>サンプルニュース</title>
<link>https://www.example.com/</link>
<description>サンプルニュースのRSSフィード</description>
<language>en-us</language>
<pubDate>Tue, 10 Jun 2003 04:00:00 GMT</pubDate>
<lastBuildDate>Fri, 21 Jul 2023 09:04 EDT</lastBuildDate>
<docs>https://www.rssboard.org/rss-specification</docs>
<generator>Blosxom 2.1.2</generator>
<managingEditor>hoge@example.com (名前)</managingEditor>
<webMaster>sample@example.com (ウェブマスター)</webMaster>
<atom:link href="https://www.example.com/rss.xml" rel="self" type="application/rss+xml" />
<item>
<title>エントリータイトル</title>
<link>http://www.example.com/sample</link>
<description>エントリーの説明文</description>
<pubDate>Fri, 21 Jul 2023 09:04 EDT</pubDate>
<guid>https://www.example.com/sample</guid>
</item>
</channel>
</rss>上記のうち、必須の要素はtitle、link、descriptionの3つだけです。itemについても省略できますが、itemを記載する場合にはtitle、もしくはdescriptionのどちらか一つは含める必要があります。
そのため、以下のような構成が最低限は必要になります。
■RSS 2.0の最低限の構成
<?xml version="1.0"?>
<rss version="2.0" xmlns:atom="http://www.w3.org/2005/Atom">
<channel>
<title>サンプルニュース</title>
<link>https://www.example.com/</link>
<description>サンプルニュースのRSSフィード</description>
</channel>
</rss>この場合、itemがないため、まだ記事を一つも更新していないサイトになるかと思います。
そのほか、itemにはpubDateも含めておきたいところです。また、linkのURLは変更される可能性があるため、itemを一意に識別する文字列としてguidがあります。加えて、rssファイル自身のURLを指定するatom:linkもあります。
さらに、文字コードのencoding="UTF-8"も指定することもおすすめします。
■おすすめの構成
<?xml version="1.0" encoding="UTF-8"?> <rss version="2.0" xmlns:atom="http://www.w3.org/2005/Atom"> <channel> <title>サンプルニュースの最新記事(RSS)</title> <link>https://www.example.com/</link> <description>サンプルニュースのRSSフィード</description> <atom:link href="https://www.example.com/rss.xml" rel="self"/> <item> <title>記事のタイトル</title> <link>https://www.example.com/sample.html</link> <description>記事の要約テキスト...</description> <pubDate>Wed, 08 Apr 2026 10:00:00 +0900</pubDate> <guid>https://www.example.com/sample.html</guid> </item> </channel> </rss>
これをPythonで自動化するコードの例は以下のようになります。
■rss.pyのサンプル
赤字の箇所は当サイト固有のものになるため、適宜修正してください。
import os import json import copy from bs4 import BeautifulSoup from feedgen.feed import FeedGenerator from datetime import datetime, timezone, timedelta # --- 設定項目 --- BASE_DIR = os.path.dirname(os.path.abspath(__file__)) OUTPUT_DIR = os.path.join(BASE_DIR, 'output') OUTPUT_PATH = os.path.join(OUTPUT_DIR, 'rss.xml') SOURCE_DIR = r'C:\Users\ホームページファイルのパス' SITEMAP_PATH = os.path.join(SOURCE_DIR, 'sitemap.xml') SITE_URL = 'https://www.example.com/' JST = timezone(timedelta(hours=+9)) def get_local_path(url): relative_path = url.replace(SITE_URL, '').replace('/', os.sep) if relative_path.endswith(os.sep) or not relative_path: relative_path = os.path.join(relative_path, 'index.html') return os.path.join(SOURCE_DIR, relative_path) def extract_info(file_path, url): if not os.path.exists(file_path): return None try: with open(file_path, 'r', encoding='utf-8') as f: soup = BeautifulSoup(f, 'html.parser') json_ld = soup.find('script', type='application/ld+json') if not json_ld: return None data = json.loads(json_ld.string) if isinstance(data, list): data = data[0] # 基準:datePublished(公開日) date_str = data.get('datePublished') if not date_str: return None dt = datetime.fromisoformat(date_str).replace(microsecond=0) if dt.tzinfo is None: dt = dt.replace(tzinfo=JST) title = data.get('headline') or (soup.title.string if soup.title else "No Title") content = "" main_tag = soup.find('main') if main_tag: temp_main = copy.copy(main_tag) # 1. h1(タイトル)を削除 if temp_main.h1: temp_main.h1.decompose() # 2. id="published"(日付段落)を削除 published_tag = temp_main.find(id="published") if published_tag: published_tag.decompose() # 3. 本文のみを抽出 content = temp_main.get_text(strip=True)[:150] + "..." else: content = "" return {'title': title, 'date': dt, 'url': url, 'desc': content} except: return None def main(): if not os.path.exists(OUTPUT_DIR): os.makedirs(OUTPUT_DIR) print(f"フォルダを作成しました: {OUTPUT_DIR}") if not os.path.exists(SITEMAP_PATH): print(f"sitemap.xmlが見つかりません。") return with open(SITEMAP_PATH, 'r', encoding='utf-8') as f: urls = [loc.text for loc in BeautifulSoup(f, 'xml').find_all('loc')] entries = [] print(f"{len(urls)} 件のファイルをスキャン中...") for url in urls: info = extract_info(get_local_path(url), url) if info: entries.append(info) if not entries: print("公開日が設定された記事が見つかりませんでした。") return # 日付でソート(最新5件を抽出して逆順にする) entries.sort(key=lambda x: x['date'], reverse=True) final_entries = entries[:5] final_entries.reverse() # --- RSSフィード生成 --- fg = FeedGenerator() fg.id(SITE_URL) fg.title('サイト名 最新記事(RSS)') # RSS 2.0 必須項目 fg.description('サイト名の最新情報をお届けします。') fg.link(href=f"{SITE_URL}rss.xml", rel='self') fg.link(href=SITE_URL, rel='alternate') fg.language('ja') # RSS 2.0 の最終更新日時タグ(lastBuildDate) fg.lastBuildDate(datetime.now(JST).replace(microsecond=0)) for item in final_entries: fe = fg.add_entry() fe.id(item['url']) fe.title(item['title']) fe.link(href=item['url']) # RSSでは pubDate を使用 fe.pubDate(item['date']) # RSSのアイテム説明 fe.description(item['desc']) # RSSファイルとして保存 fg.rss_file(OUTPUT_PATH, pretty=True) print("-" * 30) print(f"RSSフィードを生成しました: {OUTPUT_PATH}") if __name__ == '__main__': main()
実行すると、「output」フォルダ内にrss.xmlファイルが出来ているはずですので、サーバーにアップロードしましょう。
最後に、赤字の箇所を修正した上で、htmlのheadタグ内に以下のコードを設定すれば完了です。
<link rel="alternate" type="application/rss+xml" title="サイト名 最新記事 (RSS 2.0)" href="https://www.example.com/rss.xml">トップページにだけ記載するのでも問題はないかと思います。
RSSフィード作成アプリの作り方
上記のコードについては、ボタンを押せば、それぞれのファイルが実行されるようにアプリ化しておくと便利です。
以下のように「rss」フォルダ等を作成した上で、上記のatom.pyやrss.pyをまとめて入れておき、さらにree-app.pyを作成してアプリ化します。
このrss-app.pyをクリックすると、アプリが起動するようになります。
■rss-app.pyのサンプル
import os import tkinter as tk from tkinter import messagebox import importlib # 各スクリプトをインポート # ファイル名が atom.py, rss.py であることを前提としています try: import atom import rss except ImportError as e: print(f"エラー: スクリプトが見つかりません。 {e}") class RSSApp: def __init__(self, root): self.root = root self.root.title("RSS/Atom Feed Generator") self.root.geometry("400x250") # 基準ディレクトリ(rssフォルダ) self.base_dir = os.path.dirname(os.path.abspath(__file__)) self.output_dir = os.path.join(self.base_dir, 'output') # レイアウト作成 self.create_widgets() def create_widgets(self): label = tk.Label(self.root, text="フィード生成ツール", font=("Helvetica", 16, "bold")) label.pack(pady=20) # Atom作成ボタン self.btn_atom = tk.Button(self.root, text="Atomフィードを作成", command=lambda: self.run_generator("atom"), width=25, height=2, bg="#e1f5fe") self.btn_atom.pack(pady=10) # RSS作成ボタン self.btn_rss = tk.Button(self.root, text="RSSフィードを作成", command=lambda: self.run_generator("rss"), width=25, height=2, bg="#fff9c4") self.btn_rss.pack(pady=10) def run_generator(self, mode): # ファイル名の決定 filename = "atom.xml" if mode == "atom" else "rss.xml" file_path = os.path.join(self.output_dir, filename) # 1. 上書き確認 if os.path.exists(file_path): result = messagebox.askyesno("上書き確認", f"既に {filename} が存在します。\n上書きしてよろしいですか?") if not result: return # 「いいえ」なら中断 # 2. 実行 try: if mode == "atom": # importlibで最新の状態を読み込み直して実行 importlib.reload(atom) atom.main() else: importlib.reload(rss) rss.main() messagebox.showinfo("完了", f"{filename} を正常に生成しました。") except Exception as e: messagebox.showerror("エラー", f"生成中にエラーが発生しました:\n{str(e)}") if __name__ == "__main__": root = tk.Tk() app = RSSApp(root) root.mainloop()
最終的にこのようなアプリが出来上がりましたので、記事を更新した際にボタンを押せば、簡単にフィードを更新することができます。
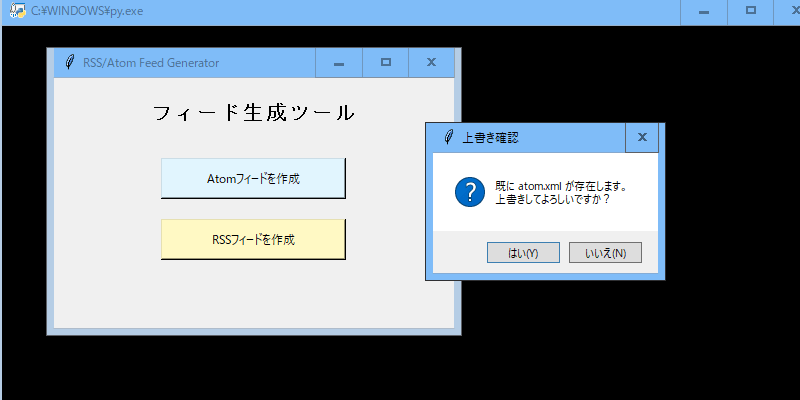
赤い文字の箇所を変更すれば、上記の表示内容を変更することができます。
出力先フォルダは「output」にしましたが、特に問題がなければ、ホームページフォルダに直接出力させるようにしてもよいと思います。